介绍
水平 Pod 自动扩缩(HPA) 根据 CPU、内存或其他自定义指标的利用率,自动调整 Deployment 或 StatefulSet 的副本数,实现弹性伸缩。
{kind=link}
为什么需要 HPA?
- ✅ 应对流量波动:节假日促销、突发热点事件
- ✅ 节省成本:低峰期自动缩容,减少资源占用
- ✅ 提升稳定性:避免手动扩缩容延迟或遗漏
- ✅ 指标驱动:基于真实指标而非猜测
快速开始
前提条件
- 目标 Deployment/StatefulSet 已配置 资源请求(requests)
- 集群已安装 metrics-server(提供 CPU/内存指标)
验证:
kubectl top nodes # 应返回节点资源使用
kubectl top pods -n <namespace>
启用 HPA
- 进入目标工作负载详情页
- 点击 操作 → 添加容器组水平自动扩缩 (HPA)
- 填写表单:
| 字段 | 说明 | 示例 |
|---|---|---|
| HPA 名称 | 自动填充,可修改 | myapp-hpa |
| 最小副本数 | HPA 不会缩容到低于此值 | 2 |
| 最大副本数 | HPA 不会扩容到超过此值 | 10 |
| CPU 使用率目标 | CPU 利用率达到多少时扩容(%),留空则不监控 | 80% |
| 内存使用率目标 | 内存利用率目标(%),留空则不监控 | 70% |
- 点击 添加
查看 HPA 状态
在 工作负载操作 页面或 HPA 列表:
- 当前副本数 / 目标副本数
- 当前 CPU 使用率 / 目标
- 当前内存使用率 / 目标
- 上次调整时间
点击 HPA 名称查看详情,包括历史调整记录。
详细说明
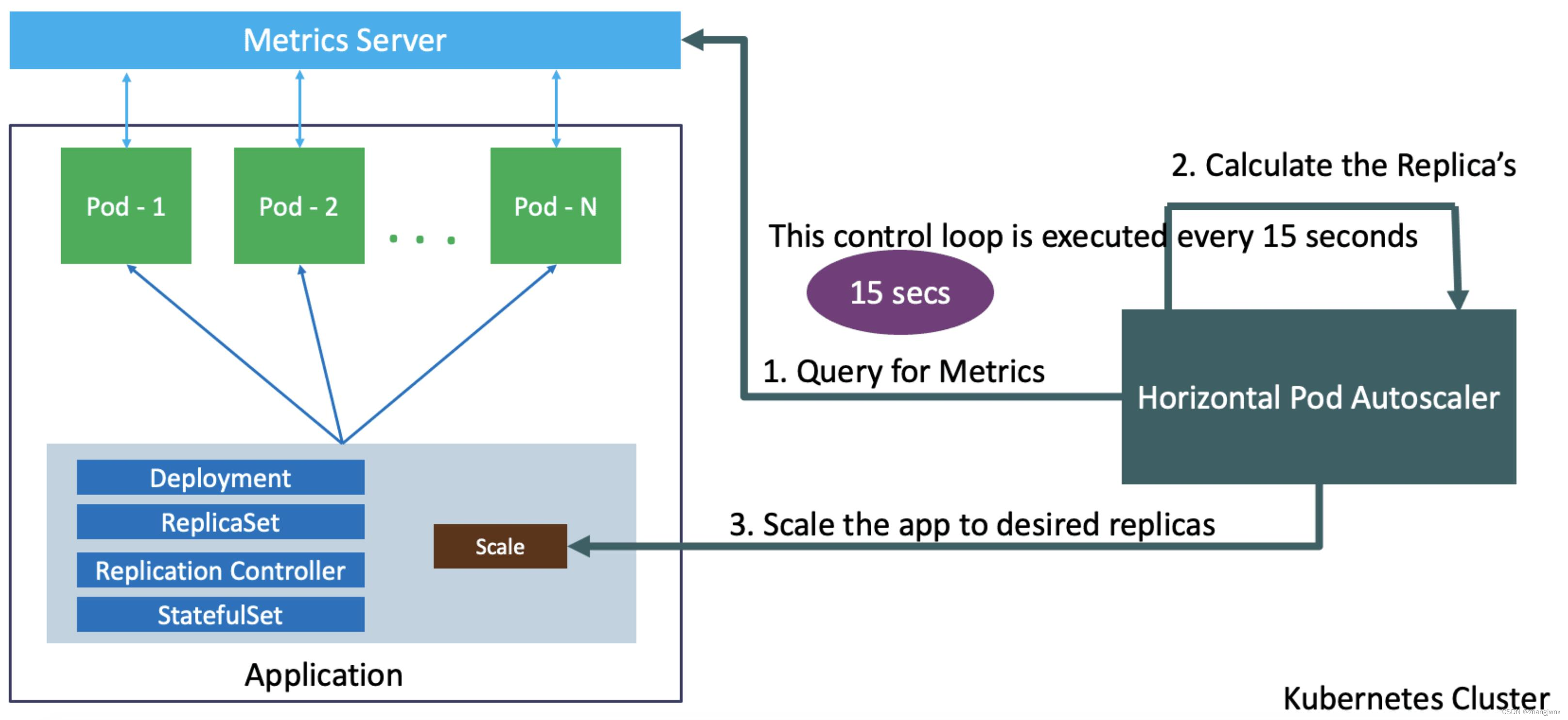
HPA 工作原理
1. HPA 控制器定期(默认 15 秒)查询 metrics-server
2. 获取目标 Deployment 的 Pod 资源使用率
3. 计算:
- 当前使用率 / 目标使用率 = 所需副本数
- 示例:目标 80%,实际 160% → 需要 ×2 = 6 个副本(当前 3 个)
4. 调整 Deployment.replicas 到计算值(介于 min/max 之间)
5. Deployment 控制器执行滚动更新
多指标 HPA
Kubernetes 1.23+ 支持同时监控多个指标,取各指标计算副本数的最大值作为最终调整值。
例如:
- CPU 利用率 100% → 需要 4 副本
- 内存利用率 90% → 需要 5 副本
HPA 最终设置副本数为 5。
自定义指标
除了 CPU/内存,HPA 还可以基于自定义指标(如 QPS、队列长度)扩缩容,需要额外配置:
- 安装 Prometheus Adapter 或自定义 Metrics API
- 在 HPA 中添加
metrics类型Pod或Object - 示例: ```yaml metrics:
- type: Pods pods: metric: name: http_requests_per_second target: type: AverageValue averageValue: 1000 ```
KDO 当前 UI 仅支持 CPU/内存指标。如需自定义指标,使用 kubectl 编辑 HPA YAML。
典型配置
场景 1:Web 应用,CPU 驱动
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 80
行为:
- CPU 平均使用率 < 80% → 缩容到 2
- CPU 平均使用率 > 80% → 扩容到 max 10
场景 2:内存敏感应用
minReplicas: 3
maxReplicas: 20
metrics:
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 75
场景 3:多指标组合
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 80
HPA 会分别计算 CPU 和内存所需的副本数,取较大值。
最佳实践
参数设置
- 🎯 minReplicas:至少 2(保证高可用),除非是 dev 环境
- 🎯 maxReplicas:根据集群容量和业务峰值设置,留 20% 缓冲
- 🎯 目标利用率:CPU 60-80%,内存 70-85%(留出突发缓冲)
- 🎯 初始副本数:创建 HPA 时,Deployment 副本数应在 min-max 之间,否则 HPA 会立即调整
稳定性
- ⏳ 扩缩容冷却:HPA 默认有
behavior控制稳定窗口(避免抖动)behavior: scaleDown: stabilizationWindowSeconds: 300 # 缩容冷却 5 分钟 policies: - type: Percent value: 10 periodSeconds: 60 - ⏳ 避免频繁抖动:如果业务流量稳定,考虑提高目标利用率或缩小 min/max 范围
配合其他组件
- 🔄 PDB:HPA 缩容时,PDB 可能阻止(要求 minAvailable)
- 🔄 ResourceQuota:确保 maxReplicas 不会超过命名空间配额
- 🔄 ClusterAutoscaler:如果节点资源不足,HPA 扩容 Pod 但节点不够,ClusterAutoscaler 会自动加节点
故障排查
HPA 不扩缩?
检查:
# 查看 HPA 状态
kubectl get hpa <name> -n <namespace>
kubectl describe hpa <name> -n <namespace>
# 查看事件
kubectl get events -n <namespace> --field-selector involvedObject.name=<hpa-name>
# 查看 metrics 是否正常
kubectl top pods -n <namespace> --label-selector=<deployment-label>
可能原因:
- Deployment 副本数不在 min-max 范围(HPA 会立即调整)
- metrics-server 未安装或数据为空
- Pod 未设置 requests(HPA 无法计算利用率)
- 当前使用率 < 目标,且副本数已处于最小值(或 > 目标且处于最大值)
HPA 扩容后 Pod 调度失败?
- 节点资源不足(CPU/内存)
- 节点选择器/污点不匹配
- 镜像拉取失败
此时 HPA 会持续尝试扩容,但 Pod 创建失败。需要解决调度问题或增加节点。
如何手动暂时禁用 HPA?
删除 HPA 对象:
kubectl delete hpa <name> -n <namespace>
Deployment 副本数保持不变,只是不再自动调整。
恢复:重新创建 HPA(yaml apply)。